Internet Services
The Myth of Five Nines: Availability and Real-World Outages
Following the DynamoDB outage at AWS on 20 October 2025, let’s discuss availability and engineering aspiration.
What Does 99% up to 99.999% Availability Mean?
| Availability | Downtime per Year | Downtime per Month | Typical Use Case |
|---|---|---|---|
| 99% (two nines) | ~3 days, 15 hours | ~7 hours, 18 minutes | Non‑critical applications |
| 99.9% (three nines) | ~8 hours, 45 minutes | ~43 minutes | Commercial web services |
| 99.999% (five nines) | ~5 minutes, 15 seconds | ~26 seconds | Mission‑critical systems |
99% ██████████████████████████████████████████████████ ~3.6 days/year
99.9% ██████████ ~8.8 hours/year
99.999% █ ~5 minutes/year
When engineers talk about 99.999% availability (five nines), they’re describing a system designed to be online almost all the time. This level of reliability is usually reserved for mission-critical systems like telecom networks, hospitals, financial and other important web services. To achieve five 9’s, engineers build in redundancy, establish failover systems, and constantly monitor performance.
The Ripples of an Outage (Example: The DynamoDB Outage)
Outages don’t always stay contained.
Consider AWS’s DynamoDB outage on Monday, 20.10.2025. The core service went down for about 2 hours, and the impact cascaded across dependent services. Because other AWS services rely on DynamoDB, the ripple extended to 12 hours of disruption and affected millions of end users.
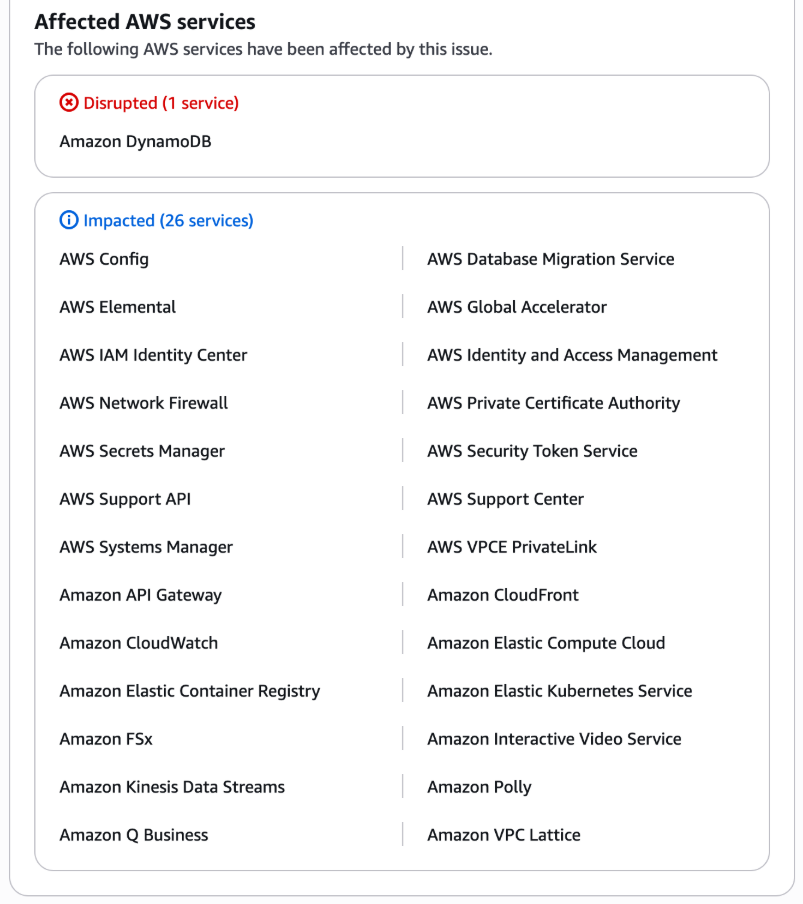
This illustrates a critical point:
- Direct downtime (the service itself being unavailable) is only part of the story.
- Indirect downtime (the ripple effect on dependent systems) can multiply the impact many times over.
So while a provider may technically meet its SLA, the real-world experience for customers can be worse. The declaration of five nines (or whatever value) is a promise, it is not an evaluated model, and is rather a design aspiration.
In a Nutshell
Cloud providers offer strong SLAs, but those numbers don’t always capture the complex interdependencies of modern distributed systems.
Network issues and secondary issues add to problems.
And, availability models do not incorporate all factors and dependencies.
Availability on paper and availability in practice can be very different stories.
🚧 For planning services, besides the SLA, one needs to consider:
- Dependencies: What other services rely on this one?
- Failure domains: How far can an outage spread?
- User impact: How does downtime affect customers?
References
For those in a haste: https://www.youtube.com/shorts/sqDStXE5mjc
The impact on other services: https://www.reuters.com/business/retail-consumer/amazons-cloud-unit-reports-outage-several-websites-down-2025-10-20/
A deep analysis: https://www.thousandeyes.com/blog/aws-outage-analysis-october-20-2025